动手数据分析笔记
第一章
第一节 数据载入及初步观察
数据载入
| |
read_csv 函数
见CSDN 博客: https://blog.csdn.net/weixin_39175124/article/details/79434022
问:read_csv 和 read_table 区别?
| 函数 | 说明 |
|---|---|
read_csv | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为逗号 |
read_table | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为制表符('\t’) |
read_fwf | 读取定宽列格式数据(也就说,没有分隔符) |
read_clipboard | 读取剪贴板中的数据,可以看作read_table的剪贴板,在将网页转换为表格时很有用。 |
问:什么是逐块读取?为什么要逐块读取呢?
| |
有chunksize参数可以进行逐块加载。经测试,它的本质就是将文本分成若干块,每次处理chunksize行的数据,最终返回一个TextParser对象
| |
查看数据基本信息
相关函数
| 函数 | 说明 |
|---|---|
df.info() | df.info():查看索引、数据类型和内存信息 |
df.head(m) | 查看表格前m行数据 |
df.tail(n) | 查看表格后n行数据 |
df.isnull().head() | 判断数据是否为空,有空的地方返回True, 其余地方返回False |
df.shape() | 查看数据列数和行数 |
df.describe() | 查看数值型列的汇总统计 |
df["列名"].unique() | 得到Series中的唯一值数组 |
df["列名"].value_counts() | 计算各值出现的次数 |
df.apply(pd.value_counts) | 唯一值,及其计数 |
预修改数据
函数
| 函数 | 说明 |
|---|---|
df = pd.read_csv('url', names=[''], ``index_col='', header=0) | 通过names,修改表头,index_col为行标签,header=0 ,以第0行为表头 |
df.insert(i,'c','data') | 在第i个位置,c为列名,data为数据 |
df['C'] = data | 在最后一列, C为列名,data为数据 |
保存数据
函数
| 函数 | 说明 |
|---|---|
df.to_csv('train_chinese.csv') | 在工作目录下新建一个’train_chinese.csv’文件 (修改后的) |
第二节 Pandas基础
Pandas 中的两种数据类型
DateFrame
二维的表格型数据结构,可以将DataFrame理解为Series的容器。
例:
| |
Series
一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
例:
| |
操作数据
| 任务 | 函数 |
|---|---|
| 查看每一列的项(查看表头) | df.columns |
| 查看某一列 | df['列名'].head() / df.列名.head() |
| 删除某行 | df.drop(['行名','行名']) |
df.drop(df.index[0], inplace=True) #删除第一行 | |
df.drop(df.index[0:3], inplace=True) #删除前三行 | |
| 删除某列 | del df[A] #就地修改 |
df = df.drop(['B', 'C'], axis=1) #不会就地修改,创建副本返回 | |
df.drop(['B', 'C'], axis=1, inplace=True)#就地修改 | |
df.drop(df.columns[0], axis=1, inplace=True) # 删除第1列 | |
| 隐藏某列 | df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head() |
| 筛选操作(通过名称筛选) | df.loc["行1","行2"] df.loc[:,"列1":"列2"] df.loc[:,["列名"]] |
df[df.年龄 > 20].head() #筛选楚年龄大于20的并展示 | |
| 筛选操作 (通过序号) | df.iloc[[100,105,108],2:5] #筛选行编号,列编号 |
| 布尔筛选 | & --> and | --> or ~ --> not #逻辑符号对应 |
df [ (条件1) 逻辑符号 (条件二) 逻辑符号 (条件三)] | |
df[df.年龄>20,["年龄"]] #筛选出年龄大于二十,只显示年龄字段 | |
| 重置索引 | reset_index(drop=True) #drop=True 不保留原来index |
reindex 参数说明

第三节 探索性数据分析
了解数据
数据排序
| 函数 | 说明 |
|---|---|
df.sort_index(axis=0) | 对行索引升序排列 |
df.sort_index(axis=1, ascending=False) | 对列索引降序排列 |
df['列名'].sort_values() | 按值对Series进行排序 |
df.sort_values(by=['列名1','列名2']) | 根据某列的值进行排序 |
df['列名'].rank(methods='' , ascending=True) | Series对原数据进行平均排名 |
df.rank(axis='columns') | 在列上进行平均排名 |
rank函数methods参数
对于泰坦尼克号数据,数据与存活率的思考
| |

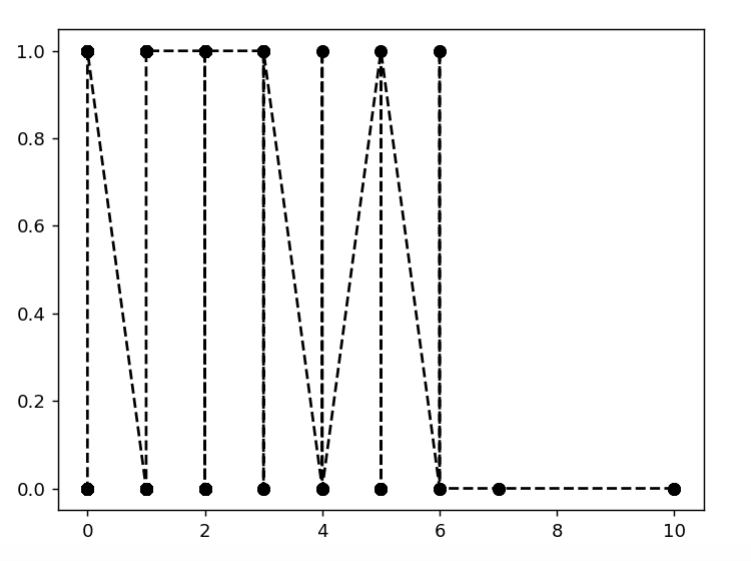
- 票价越高且年龄较小的,基本全部存活
- 家庭人数越多,存活率几乎为0
第二章
第一节 数据清洗及特征处理
数据处理
缺失值处理
缺失值观察
| 函数 | 说明 |
|---|---|
| df.isnull() | 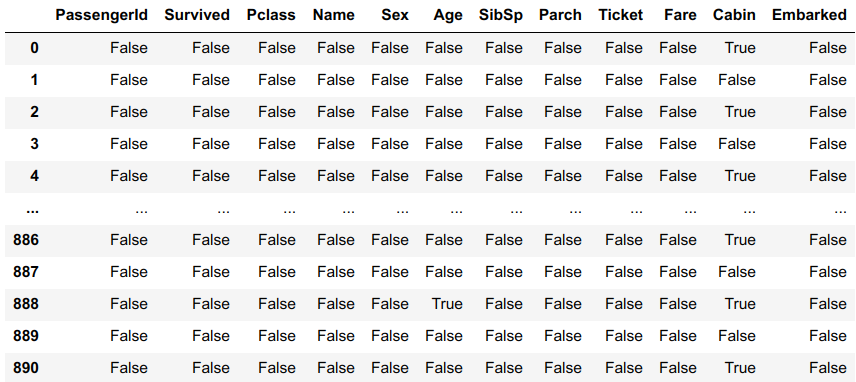 |
| df.isnull().sum() | 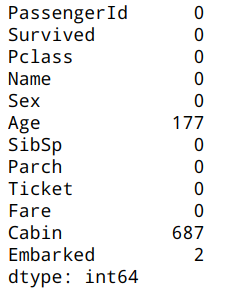 |
| df.info() | 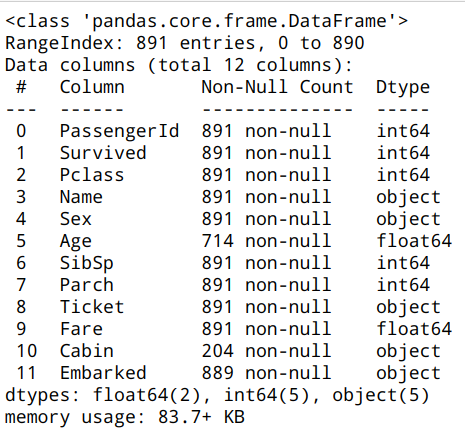 |
处理缺失值
| 函数 | 说明 |
|---|---|
df.dropna() | 根据各标签的值中是否存在缺失数据对轴标签进行过滤,可通过阈值调节对确实值的容忍度 |
df.fillna() | 用指定值或插值方法(ffill or bfill) 填充缺失数据 |
df.isnull() | 返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值/NA, 该对象的类型与源类型一样 |
notnull | isnull的否定式 |
dropna()
参数:
axis: default 0指行,1为列
how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;‘all’指清除全是缺失值的
thresh: int,保留含有int个非空值的行
subset: 对特定的列进行缺失值删除处理
inplace: 这个很常见,True表示直接在原数据上更改
fillna()
参数 :
inplace: True of False
method: {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
pad/ffill:用前一个非缺失值去填充该缺失值
backfill/bfill:用下一个非缺失值填充该缺失值
None:指定一个值去替换缺失值(缺省默认这种方式)
limit:限制填充个数
axis:修改填充方向
问:检索空缺值用np.nan要比用None好,这是为什么?
| |
数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan
对年龄(Age)缺失值处理
对年龄采用均值处理:
| |
对舱位(Cabin)处理
查看舱位基本信息
| |
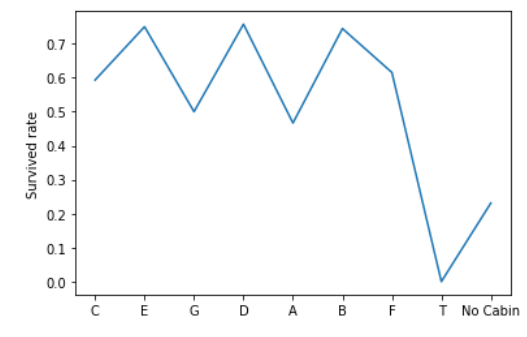
综上,客舱缺失值是无舱位,属正常现象。
客舱除T客舱外,其余存活率均维持在0.6上下,但T客舱只有一人,所以客舱无需考虑。
无客舱人数出
计算无客舱人数存活率踩坑
初步思路
| |
在 @型 from KDD🍻的帮助下,
[df.Cabin.isnull() & df.Survived == 1] ,结果为长度为1的list
想到拆分list, 采用np.split(), 将list转为np.array,发现转为np.array时,直接可拆分数组。
最终结果
| |
重复值处理
| 函数 | 说明 |
|---|---|
df['列名'].value_counts() | 查看某列的重复值,显示 值和数量 |
df['列名'].unique() | 只显示值 |
df.duplicated() | 指定列数据重复项判断 返回:指定列重复行boolean Series |
df.drop_duplicates() | 删除重复数据 返回:副本或替代 |
| |
参数: subset=None:列标签或标签序列,可选# 只考虑某些列来识别重复项;默认使用所有列 keep='first’:{‘first’,‘last’,False}
first:将第一次出现重复值标记为True
last:将最后一次出现重复值标记为True
False:将所有重复项标记为True
特征处理
数值类型变量处理
分箱操作(离散化处理)
个人理解,将数据划分不同区间,降低过拟合风险。
如:年龄,划分为不同区间,分别处理
分箱操作(离散化处理) 函数 pd.cut()
| |
x: 一维数组(对应前边例子中提到的销售业绩)
bins:整数,标量序列或者间隔索引,是进行分组的依据,
- 如果填入整数n,则表示将x中的数值分成等宽的n份(即每一组内的最大值与最小值之差约相等);
- 如果是标量序列,序列中的数值表示用来分档的分界值
- 如果是间隔索引,“ bins”的间隔索引必须不重叠
right:布尔值,默认为True表示包含最右侧的数值
- 当“ right = True”(默认值)时,则“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]
- 当
bins是一个间隔索引时,该参数被忽略。
labels: 数组或布尔值,可选.指定分箱的标签
- 如果是数组,长度要与分箱个数一致,比如“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3个区间,则labels的长度也就是标签的个数也要是3
- 如果为False,则仅返回分箱的整数指示符,即x中的数据在第几个箱子里
- 当bins是间隔索引时,将忽略此参数
retbins: 是否显示分箱的分界值。默认为False,当bins取整数时可以设置retbins=True以显示分界值,得到划分后的区间
precision:整数,默认3,存储和显示分箱标签的精度。
include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边。
duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一
文本类型变量处理
文本变量用数值表示
| 函数 | 说明 |
|---|---|
df.replace() | 参数替换 |
df.map(#dict) | map传入字典替换 |
LabelEncoder | http://www.scikitlearn.com.cn/0.21.3/46/#592 |
| |
文字 变量one-hot编码
| 函数 | 说明 |
|---|---|
| pd.get_dummies() | 将数据转化为one-hot DataFrame |
| pd.concat() | 沿着指定轴,将DataFrame 拼接在一起 |
| |
Parameters
- dataarray-like, Series, or DataFrame
Data of which to get dummy indicators.
- prefixstr, list of str, or dict of str, default None
String to append DataFrame column names. Pass a list with length equal to the number of columns when calling get_dummies on a DataFrame. Alternatively, prefix can be a dictionary mapping column names to prefixes.
- prefix_sepstr, default ‘_’
If appending prefix, separator/delimiter to use. Or pass a list or dictionary as with prefix.
- dummy_nabool, default False
Add a column to indicate NaNs, if False NaNs are ignored.
- columnslist-like, default None
Column names in the DataFrame to be encoded. If columns is None then all the columns with object or category dtype will be converted.
- sparsebool, default False
Whether the dummy-encoded columns should be backed by a
SparseArray(True) or a regular NumPy array (False).
- drop_firstbool, default False
Whether to get k-1 dummies out of k categorical levels by removing the first level.
- dtypedtype, default np.uint8
Data type for new columns. Only a single dtype is allowed.New in version 0.23.0.
Returns
- DataFrame
Dummy-coded data.
来源:官方文档
| |
objs需要连接的对象,eg [df1, df2]axisaxis = 0, 表示在水平方向(row)进行连接 axis = 1, 表示在垂直方向(column)进行连接join outer, 表示index全部需要; inner,表示只取index重合的部分join_axes传入需要保留的indexignore_index忽略需要连接的frame本身的index。当原本的index没有特别意义的时候可以使用keys可以给每个需要连接的df一个label来源:https://www.jianshu.com/p/421f040dfe2f
从Name中提取title
| |
参数: pat : 字符串或正则表达式 flags : 整型, expand : 布尔型,是否返回DataFrame Returns: 数据框dataframe/索引index
第二节 数据重构
数据理解
数据合并
| 函数 | 说明 |
|---|---|
pd.concat | 横向纵向均可 |
df.append | 纵向连接 |
df.join | 横向连接,根据相同的index进行连接 |
pd.merge | 横向连接 用于通过一个或多个键将两个数据集的行连接起来,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量 |
pd.concat(objs, axis=0,join='outer’,join_axes=None, ignore_index=False,keys=None, levels=None,
names=None, verify_integrity=False)
objs需要连接的对象,eg [df1, df2]axisaxis = 0, 表示在水平方向(row)进行连接 axis = 1, 表示在垂直方向(column)进行连接
join outer, 表示index全部需要; inner,表示只取index重合的部分join_axes传入需要保留的indexignore_index忽略需要连接的frame本身的index。当原本的index没有特别意义的时候可以使用keys可以给每个需要连接的df一个label
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
other: 是要添加的数据,append很不挑食,这个other可以是dataframe,dict,Seris,list等等。
ignore_index: 参数为True时将在数据合并后,按照0,1,2,3….的顺序重新设置索引,忽略了旧索引。
verify_integrity:参数为True时,如果合并的数据与原数据包含索引相同的行,将报错。
DataFrame.join(other, on=None, how='left’,lsuffix=’', rsuffix=’', sort=False)
other:另一个待拼接的DataFrame或者有名称列表的Series
on:连接的列名或者index, 也就是指明2个要连接的对象之间通过哪个列名或者索引名进行连接。
how:连接方式,类似sql语句中的(left ,right,inner,outer),这里默认为’left’, 可选的参数有left, right , inner , outer lsuffix: 左边的连接Key要用的下标
rsuffix: 右边的连接Key要用的下标
sort:对拼接后的列名按照字典顺序排序,默认为False,False的时候,保留按照左边的DataFrame进行排序的顺序。
pd.merge(left, right, how='inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x’, ‘_y’), copy=True, indicator=False,validate=None)
right:要连接的目标数据,类型为DataFrame或者带列名的Series
how:连接方式,类似sql语句中的(left,right,inner,outer),这里默认为’inner’, 可选的参数有left, right , inner , outer
on:连接的列名或者index, 也就是指明2个要连接的对象之间通过哪个列名或者索引名进行连接。
left_on: 指定左边的DataFrame以哪个列名或者索引名进行连接
right_on:指定右边的DataFrame以哪个列名或者索引名进行连接
left_index:用左边的DataFrame当做连接Key
right_index:用右边的DataFrame当做连接Key
sort:按照字典顺序对连接Key进行排序,默认为False,默认连接键的顺序取决于连接类型
suffixes:连接后的列名默认带下标 ('_x’ , ‘_y’)
copy:默认复制,如果设置为False,则尽可能的避免复制
a. 默认以相同的列名进行连接键
换角度看数据
| 函数 | 说明 |
|---|---|
| df.stack | 将数据的列索引旋转为行索引 |
| df.unstack | 将数据的行索引旋转为列索引 |
数据聚合和运算
数据运用
GroupBy 机制
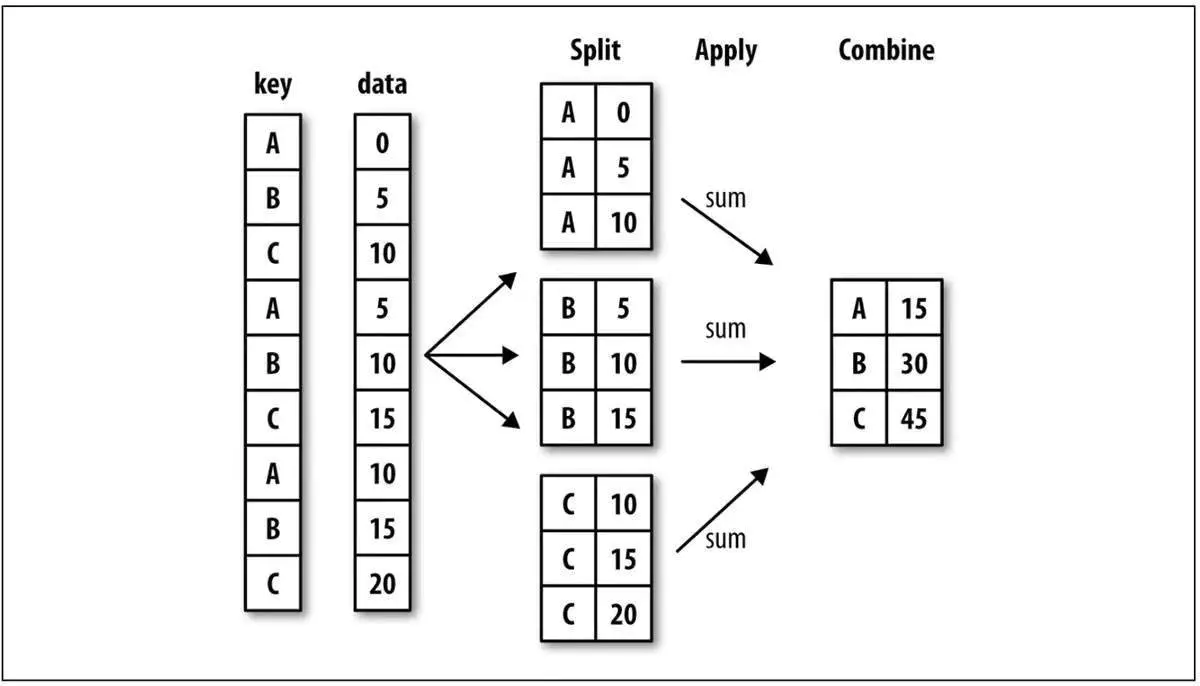
根据提供的一个或多个键分离各组,然后应用函数,产生新值
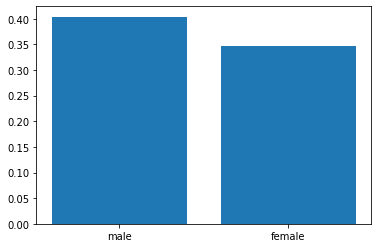
将男女存活率可视化
| |
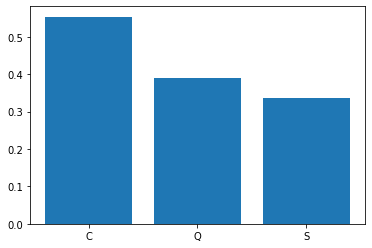
各舱位存活率可视化
| |
agg函数
| |

第三节 数据可视化
设置颜色和格式
| |

- 八种内建颜色缩写 b: blue g: green r: red c: cyan(青色,介于绿色和蓝色之间) m: magenta(洋红色,介于红色和紫色之间) y: yellow k: black w: white
- html十六进制表示颜色
- rgb元组
- 灰色阴影表示
1.线性
| 字符 | 类型 | 字符 | 类型 |
|---|---|---|---|
'-' | 实线 | '--' | 虚线 |
'-.' | 虚点线 | ':' | 点线 |
'.' | 点 | ',' | 像素点 |
'o' | 圆点 | 'v' | 下三角点 |
'^' | 上三角点 | '<' | 左三角点 |
'>' | 右三角点 | '1' | 下三叉点 |
'2' | 上三叉点 | '3' | 左三叉点 |
'4' | 右三叉点 | 's' | 正方点 |
'p' | 五角点 | '*' | 星形点 |
'h' | 六边形点1 | 'H' | 六边形点2 |
'+' | 加号点 | 'x' | 乘号点 |
'D' | 实心菱形点 | 'd' | 瘦菱形点 |
'_' | 横线点 |
| |
散点图
| |
多图绘制
| |
折线图
| |
条形图
| |
绘制水平条形图
| |
多个条形图
| |
层叠图
| |
直方图
| |
双变量直方图(用颜色深浅表示频率大小)
| |
饼状图
| |
箱形图
箱型图能显示出一组数据的最大值、最小值、中位数、及上下四分位数。
| |

![]()
Reference
CSDN: https://blog.csdn.net/qq_43212582/article/details/101473916#_120
seaborn 学习
| |
FacetGrid 使用
| |

kdeplot(核密度估计图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
基本画图
| |
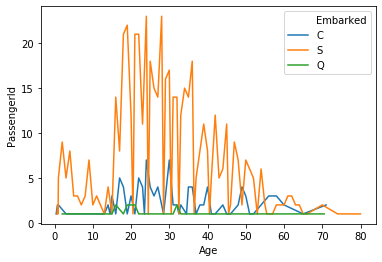
test1.head()
| Age | Embarked | PassengerId | |
|---|---|---|---|
| 0 | 0.42 | C | 1 |
| 1 | 0.67 | S | 1 |
| 2 | 0.75 | C | 2 |
| 3 | 0.83 | S | 2 |
| 4 | 0.92 | S | 1 |
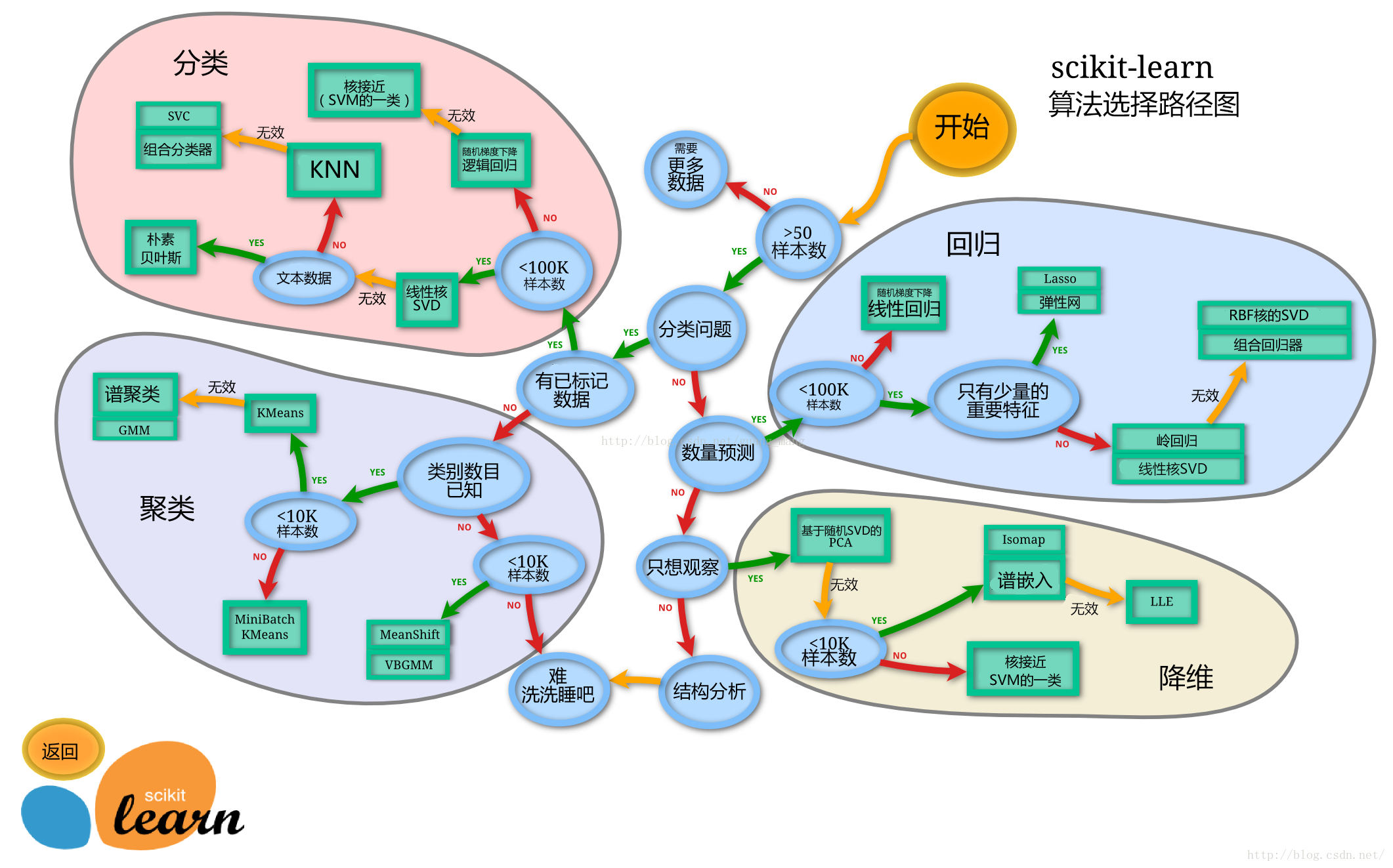
第三章 模型建立与评估
模型建立
- 处理完前面的数据我们就得到建模数据,下一步是选择合适模型
- 在进行模型选择之前我们需要先知道数据集最终是进行监督学习还是无监督学习
- 模型的选择一方面是通过我们的任务来决定的。
- 除了根据我们任务来选择模型外,还可以根据数据样本量以及特征的稀疏性来决定
- 刚开始我们总是先尝试使用一个基本的模型来作为其baseline,进而再训练其他模型做对比,最终选择泛化能力或性能比较好的模型
切割训练集和测试集
| |
| |
arrays:特征数据和标签数据(array,list,dataframe等类型),要求所有数据长度相同。
test_size / train_size: 测试集/训练集的大小,若输入小数表示比例,若输入整数表示数据个数。
rondom_state:随机种子(一个整数),其实就是一个划分标记,对于同一个数据集,如果rondom_state相同,则划分结果也相同。
shuffle:是否打乱数据的顺序,再划分,默认True。
stratify:none或者array/series类型的数据,表示按这列进行分层采样。
逻辑回归
| |
常用方法
fit(X, y, sample_weight=None)
- 拟合模型,用来训练LR分类器,其中X是训练样本,y是对应的标记向量
- 返回对象,self。
fit_transform(X, y=None, **fit_params)
- fit与transform的结合,先fit后transform。返回
X_new:numpy矩阵。
predict(X)
- 用来预测样本,也就是分类,X是测试集。返回array。
predict_proba(X)
- 输出分类概率。返回每种类别的概率,按照分类类别顺序给出。如果是多分类问题,multi_class="multinomial”,则会给出样本对于每种类别的概率。
- 返回array-like。
score(X, y, sample_weight=None)返回给定测试集合的平均准确率(mean accuracy),浮点型数值。
- 对于多个分类返回,则返回每个类别的准确率组成的哈希矩阵。
| |
决策树
| |
随机森林
| |
模型评估
交叉验证

| |
混淆矩阵
类偏科的误差度量
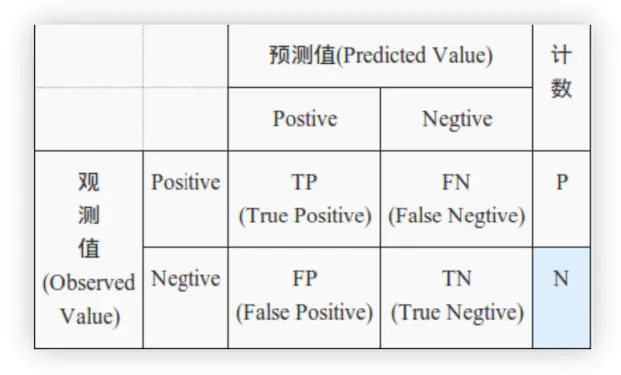
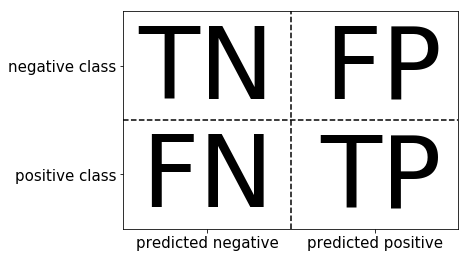

| 情况 | 英文 | 预测 | 实际 |
|---|---|---|---|
| 正确肯定 | TP | 真 | 真 |
| 正确否定 | TN | 假 | 假 |
| 错误肯定 | FP | 假 | 真 |
| 错误否定 | FN | 真 | 假 |
以经典案例恶性肿瘤病人
Precision 查准率 = $\frac {TP}{TP+FP}$ , 所有预测有恶性肿瘤的病人中,实际上有恶性肿瘤病人的百分比
Recall 查全率 = $\frac {TP}{TP+FN}$ ,实际上有恶性肿瘤的病人中,成功预测的百分比
From 吴恩达机器学习笔记
- 构造简单学习算法
- 用交叉验证集数据测试算法
- 绘制学习曲线
- 进行误差分析
| |
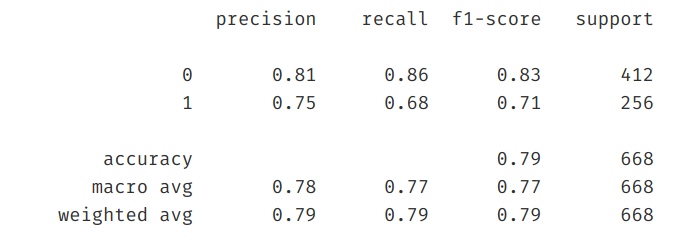
ROC曲线
什么是ROC曲线
ROC的全称是Receiver Operating Characteristic Curve,中文名字叫“受试者工作特征曲线”,顾名思义,其主要的分析方法就是画这条特征曲线。这里在网上找了一个比较好的图样示例如下,
该曲线的横坐标为假阳性率(False Positive Rate, FPR),N是真实负样本的个数, FP是N个负样本中被分类器预测为正样本的个数。
纵坐标为真阳性率(True Positive Rate, TPR)
P是真实正样本的个数, TP是P个正样本中被分类器预测为正样本的个数。 $$ TPR = \frac {TP}{TF + FN} ,\space \space FPR = \frac{FP}{FP+TN}
$$
绘制步骤
- 假设已经得出一系列样本被划分为正类的概率Score值,按照大小排序。
- 从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于某个样本,其“Score”值为0.6,那么“Score”值大于等于0.6的样本都被认为是正样本,而其他样本则都认为是负样本。
- 每次选取一个不同的threshold,得到一组FPR和TPR,以FPR值为横坐标和TPR值为纵坐标,即ROC曲线上的一点。
- 根据3中的每个坐标点,画图。
利用ROC曲线评价模型性能——AUC(Area Under Curve)
AUC表示ROC曲线下的面积,主要用于衡量模型的泛化性能,即分类效果的好坏。AUC是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。一般在分类模型中,预测结果都是以概率的形式表现,如果要计算准确率,通常都会手动设置一个阈值来将对应的概率转化成类别,这个阈值也就很大程度上影响了模型准确率的计算。
之所以采用AUC来评价,主要还是考虑到ROC曲线本身并不能直观的说明一个分类器性能的好坏,而AUC值作为一个数量值,具有可比较性,可以进行定量的比较。
AUC值的计算方法:
- 将坐标点按照横坐标FPR排序 。
- 计算第$i$个坐标点和第$i+1$个坐标点的间距$dx$ 。
- 获取第$i$或者个$i+1$坐标点的纵坐标y。
- 计算面积微元 $ds = ydx$
- 对面积微元进行累加,得到AUC。
AUC值对模型性能的判断标准:
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
利用ROC曲线选择最佳模型
首先了解一下ROC曲线图上很重要的四个点:
- 第一个点$(0,1)$,即FPR=0, TPR=1,这意味着FN(False Negative)=0,并且FP(False Positive)=0。意味着这是一个完美的分类器,它将所有的样本都正确分类。
- 第二个点$(1,0)$,即FPR=1,TPR=0,意味着这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
- 第三个点$(0,0)$,即FPR=TPR=0,即FP(False Positive)=TP(True Positive)=0,可以发现该分类器预测所有的样本都为负样本(Negative)。
- 第四个点$(1,1)$,即FPR=TPR=1,分类器实际上预测所有的样本都为正样本。
==ROC曲线图中,越靠近(0,1)的点对应的模型分类性能越好。==而且可以明确的一点是,ROC曲线图中的点对应的模型,它们的不同之处仅仅是在分类时选用的阈值(Threshold)不同,每个点所选用的阈值都对应某个样本被预测为正类的概率值。
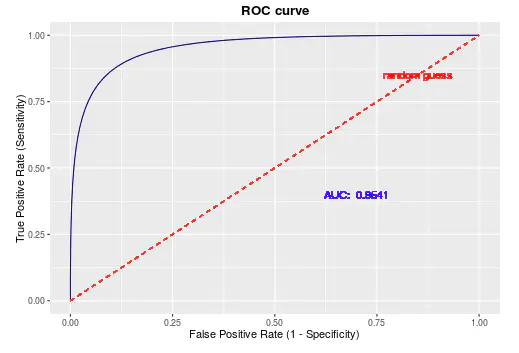
不同模型之间选择最优模型
当然最直观的比较方式就是基于AUC值,不同的模型对应的ROC曲线中,AUC值大的模型性能自然相对较好。而当AUC值近似相等时,有两种情况:第一种是ROC曲线之间没有交点;第二种是ROC曲线之间存在交点。在两个模型AUC值相等时,并不代表两个模型的分类性能也相等。
ROC曲线之间没有交点
如下图所示,A,B,C三个模型对应的ROC曲线之间交点,且AUC值是不相等的,此时明显更靠近(0,1)(0,1)(0,1)点的A模型的分类性能会更好。
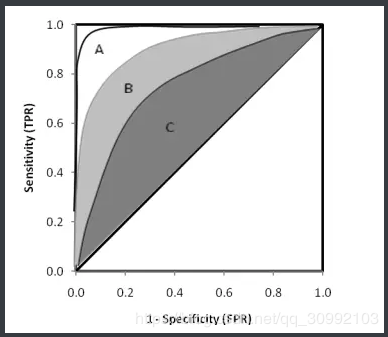
ROC曲线之间存在交点
如下图所示,模型A、B对应的ROC曲线相交却AUC值相等,此时就需要具体问题具体分析:当需要高Sensitivity值时,A模型好过B;当需要高Specificity值时,B模型好过A。
更多参考 : https://blog.csdn.net/qq_30992103/article/details/99730059
对于多分类的ROC
经典的ROC曲线适用于对二分类问题进行模型评估,通常将它推广到多分类问题的方式有两种:
- 对于每种类别,分别计算其将所有样本点的预测概率作为阈值所得到的$TPR$值(是这种类别为正,其他类别为负),最后将每个取定的阈值下,对应所有类别的$TPR$值和$FPR$值分别求平均,得到最终对应这个阈值的$TPF$和$F PR $值
- 首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。
上面的两个方法得到的ROC曲线是不同的,当然曲线下的面积AUC也是不一样的。 在python中,方法1和方法2分别对应sklearn.metrics.roc_auc_score函数中参数average值为’macro’和’micro’的情况。