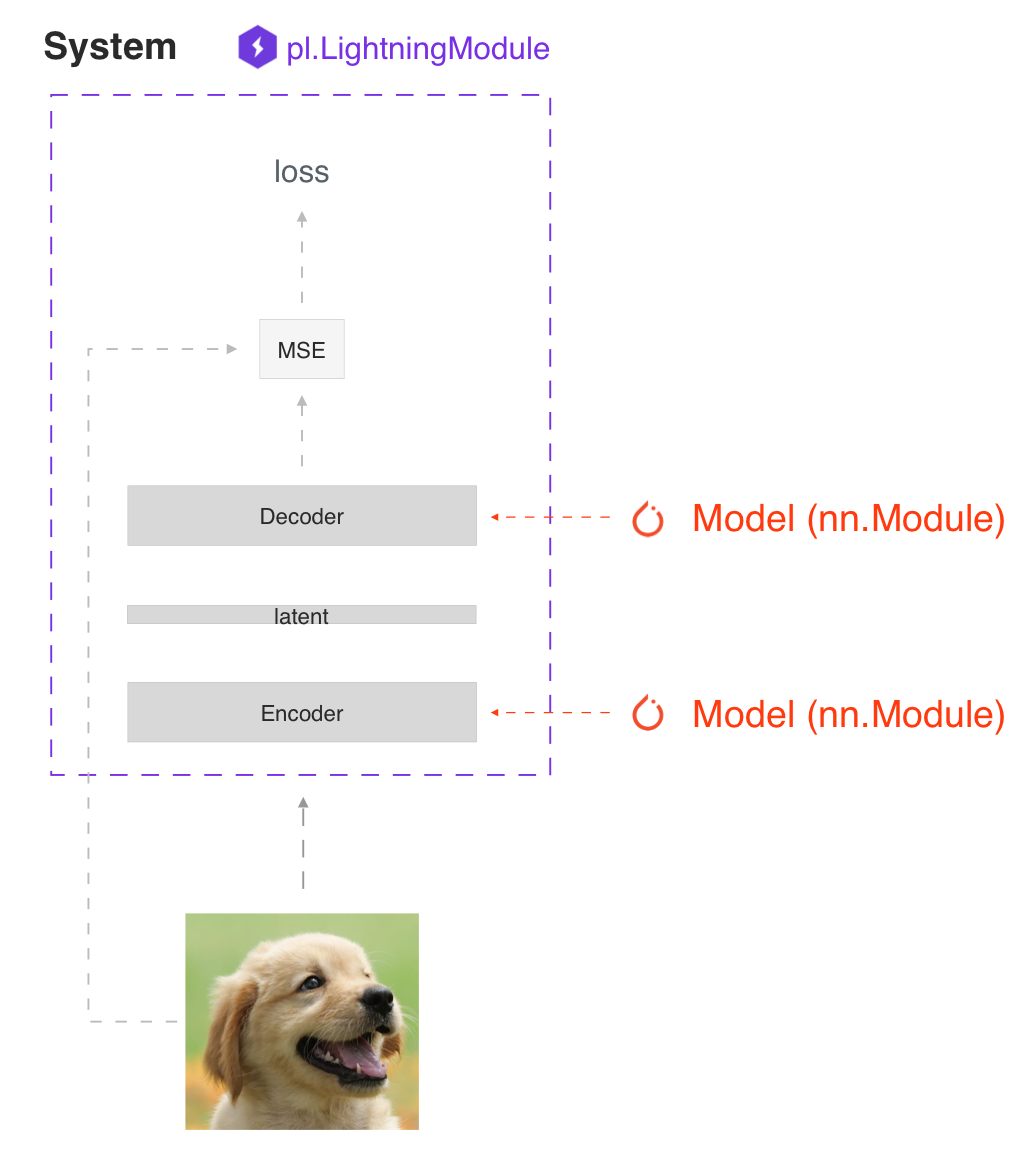
classLitAutoEncoder(pl.LightningModule):def__init__(self):super().__init__()self.encoder=nn.Sequential(nn.Linear(28*28,64),nn.ReLU(),nn.Linear(64,3))self.decoder=nn.Sequential(nn.Linear(3,64),nn.ReLU(),nn.Linear(64,28*28))defforward(self,x):# in lightning, forward defines the prediction(预测)/inference(推理) actionsembedding=self.encoder(x)returnembeddingdeftraining_step(self,batch,batch_idx):# training_step defined the train loop.# It is independent of forwardx,y=batchx=x.view(x.size(0),-1)z=self.encoder(x)x_hat=self.decoder(z)loss=F.mse_loss(x_hat,x)# Logging to TensorBoard by defaultself.log('train_loss',loss)#self.log('my_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)returnlossdefconfigure_optimizers(self):optimizer=torch.optim.Adam(self.parameters(),lr=1e-3)returnoptimizer
# init modelautoencoder=LitAutoEncoder()# most basic trainer, uses good defaults (auto-tensorboard, checkpoints, logs, and more)# trainer = pl.Trainer(gpus=8) (if you have GPUs)trainer=pl.Trainer()trainer.fit(autoencoder,train_loader)
The Trainer automates:
Epoch and batch iteration
Calling of optimizer.step(), backward, zero_grad()
# ----------------------------------# to use as embedding extractor# ----------------------------------autoencoder=LitAutoEncoder.load_from_checkpoint('path/to/checkpoint_file.ckpt')encoder_model=autoencoder.encoderencoder_model.eval()# ----------------------------------# to use as image generator# ----------------------------------decoder_model=autoencoder.decoderdecoder_model.eval()
Option 2: Forward
1
2
3
4
5
6
7
8
9
10
# ----------------------------------# using the AE to extract embeddings# ----------------------------------classLitAutoEncoder(pl.LightningModule):defforward(self,x):embedding=self.encoder(x)returnembeddingautoencoder=LitAutoencoder()autoencoder=autoencoder(torch.rand(1,28*28))
1
2
3
4
5
6
7
8
9
10
11
12
# ----------------------------------# or using the AE to generate images# ----------------------------------classLitAutoEncoder(pl.LightningModule):defforward(self):z=torch.rand(1,3)image=self.decoder(z)image=image.view(1,1,28,28)returnimageautoencoder=LitAutoencoder()image_sample=autoencoder()
# train on 8 CPUstrainer=pl.Trainer(num_processes=8)
1
2
3
4
5
# train on 1024 CPUs across 128 machinestrainer=pl.Trainer(num_processes=8,num_nodes=128)
1
2
# train on 1 GPUtrainer=pl.Trainer(gpus=1
1
2
3
4
5
# train on multiple GPUs across nodes (32 gpus here)trainer=pl.Trainer(gpus=4,num_nodes=8)
1
2
# train on gpu 1, 3, 5 (3 gpus total)trainer=pl.Trainer(gpus=[1,3,5])
1
2
# Multi GPU with mixed precisiontrainer=pl.Trainer(gpus=2,precision=16)
1
2
# Train on TPUstrainer=pl.Trainer(tpu_cores=8)
无需修改代码中的任意一行,就可以使用上面的代码执行以下操作。
1
2
3
4
5
6
7
8
# train on TPUs using 16 bit precision# using only half the training data and checking validation every quarter of a training epochtrainer=pl.Trainer(tpu_cores=8,precision=16,limit_train_batches=0.5,val_check_interval=0.25)
Checkpoints
Lightning会自动保存你的模型,一旦你训练好了,你可以通过下面代码来加载检查点
1
model=LitModel.load_from_checkpoint(path)
上面的检查点包含了初始化模型和设置状态字典所需的所有参数
1
2
3
4
5
6
# load the ckptckpt=torch.load('path/to/checkpoint.ckpt')# 等效与上述代码model=LitModel()model.load_state_dict(ckpt['state_dict'])