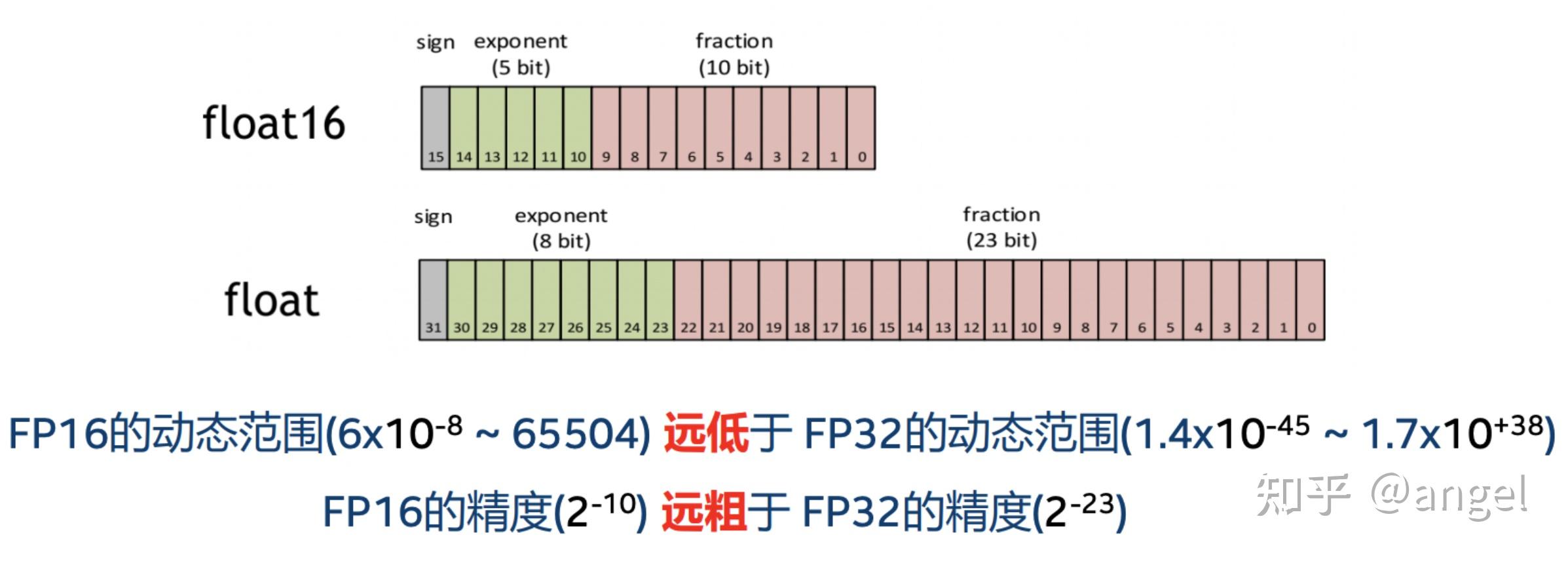
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| def draw_boxes(img, bbox, identities=None, offset=(0, 0)):
for i, box in enumerate(bbox):
x1, y1, x2, y2 = [int(i) for i in box]
x1 += offset[0]
x2 += offset[0]
y1 += offset[1]
y2 += offset[1]
# box text and bar
id = int(identities[i]) if identities is not None else 0
color = compute_color_for_labels(id)
label = '{}{:d}'.format("", id)
t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 2, 2)[0]
cv2.rectangle(img, (x1, y1), (x2, y2), color, 3)
cv2.rectangle(
img, (x1, y1), (x1 + t_size[0] + 3, y1 + t_size[1] + 4), color, -1)
cv2.putText(img, label, (x1, y1 +
t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 2, [255, 255, 255], 2)
return img
def draw_trace(img, bbox, identities=None):
for i, box in enumerate(bbox):
x1, y1, x2, y2 = [int(i) for i in box]
x = (x1 + x2) // 2
y = (y1 + y2) // 2
id = int(identities[i]) if identities is not None else 0
color = compute_color_for_labels(id)
if id in trace.keys():
trace[id].append((x, y))
temp = trace[id]
for i in range(1, len(temp)):
cv2.line(img, (temp[i-1][0], temp[i-1][1]), (temp[i][0], temp[i][1]), color, 3)
if i > 20:
temp.pop(0)
else:
trace[id] = [(x, y)]
|